Here are some examples of how foundation models can be used in a UNIX-like environment. A model is considered foundational when it has been trained on a large and diverse dataset, enabling it to be used out-of-the-box or fine-tuned for a wide range of downstream tasks.
In most of these examples, classic and modern UNIX utilities are used to stitch together different tools. A foundation model is then applied to tackle problems that go beyond well-defined solutions. Finally, UNIX utilities are used again to constrain, refine, or reshape the model’s output, transforming it into something useful.

Creating playlists
Consider a scenario where you have downloaded
a number of songs and want to organize them into playlists. Manually
selecting tracks so that they smoothly transition from one to the other
can be time-consuming and requires intimacy with one’s music collection.
However, by using a model that understands music and sound to translate
each song into a point in space, and then interpolating between these
points, it is possible to automatically create coherent playlists. This
recipe takes advantage of the llm1 utility and some
accompanying plugins,2 but the technique can be implemented using
analogous tools.
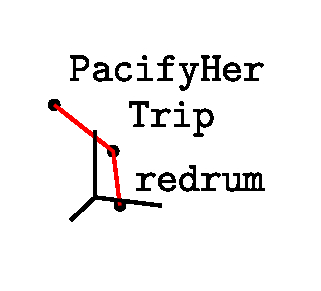 A model that understands audio can be used to embed our music
collection (
A model that understands audio can be used to embed our music
collection ($MC) into a high-dimensional space, where similar songs are
placed closer together. With the llm-clap plugin, we can generate
embeddings for our collection using the CLAP model with
llm embed-multi -m clap songs --files $MC '*' Now, each one of
our songs and its corresponding embedding are saved in a local
embeddings.db database, which we can query. Then, the
llm-interpolate plugin returns interpolated points between a starting
and ending point (song), creating between them a path (playlist). For
example, this one-liner generates a 5-song .m3u playlist between
PacifyHer.wav and redrum.wav:
llm interpolate songs "PacifyHer" "redrum" -n 5 | jq .[] > playlist.m3u
Taking notes
It can be tricky to take notes while watching videos of talks.
A model that can generate summaries of the video content can be used to
generate notes, which can be reviewed and expanded upon later. This can
also help rapidly expand one’s set of notes. The following two-liner
uses the llm utility to generate a summary of a video
transcript downloaded using yt-dlp and finally pipes the output
to create a new note object using zk.3
yt-dlp --no-download --write-subs --output "$OUT" "$URL"
cat "$OUT" | llm -s "Create notes" | zk new -i
Generating reports
It is common practice for people working together to have monthly, weekly, or even daily meetings where all members give a short update on what they have been working on. These reports can be frustrating as they demand the right level of abstraction—neither too detailed for team members lacking context nor too broad to allow meaningful feedback. Forgetting the specifics of your recent work adds to the challenge.
Digital todo-list tools like taskwarrior4 can be leveraged
to generate these reports by smartly querying them and piping their
output into an LLM. The following pipeline (1) queries taskwarrior for
all of last week’s completed tasks, (2) exports them in json format, (3)
uses jq5 to extract the .description attribute from
each one, and (4) provides the completed task list to an LLM asking it
to generate the report.
task status:completed end.after:today-7d export |
jq '.[] | .description' |
llm -s 'Generate a report based on these tasks.'
Renaming pictures
Consider the scenario where you have a large collection of pictures saved. If these pictures are taken by you, or downloaded from the internet, chances are the image files have vague or useless names.
$ ls
1672714705640839.png 1689964585834142.png 2.jpg
The laborious process of renaming each one can be automated by
leveraging a model with image-understanding capabilities. For this
recipe, one can use ollama,6 a very usable LLM model
fetching and inference tool that works great out-of-box with the
moondream vision model, which is small enough to allow for
quick inference on a modern laptop. The following pipeline finds every
.jpg file in the current directory and asks the model to
provide a title for it based on the image contents, some light
formatting at the end makes whatever the model outputs into a plausible
filename.
find . -name "*.jpg" |
xargs -I{} ollama run moondream "Title for this: {}" |
tr ' ' '_' | sed 's/$/\.jpg/'
The (slightly truncated) output filenames are (zoom-in to confirm):
A_green_dragon_with_wings_and_a_tail.jpg  ,
,
A_painting_of_a_serene_landscape.jpg  ,
,
urns_of_stone_red_car_in_foreground.jpg  .
.
Conclusion
This article serves as a starting inspiration point for the community to start using these technologies for fun and profit. Please reach out with thoughts and ideas.
This article is part of Paged Out! magazine, issue #6. You can get a free PDF of the magazine on the Paged Out! website.